키-값 저장소란?
키-값 저장소(key-value store)는 키-값 데이터베이스라고도 불리는 비 관계형(non-relational) 데이터베이스이다.
이 저장소에 저장되는 값은 고유 식별자(identifier)를 키로 가져야 한다.
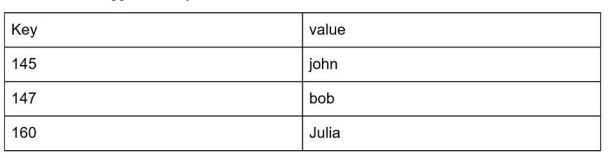
키와 값 사이의 이런 연결 관계를 "키-값" 쌍(pair)이라고 지칭한다. java - (map)
이번 장에선 다음 연산을 지원하는 키-값 저장소를 설계해보자.
- put(key, value): 키-값 쌍을 저장소에 저장한다.
- get(key): 인자로 주어진 키에 매달린 값을 꺼낸다.
문제 이해 및 설계 범위 설정
읽기, 쓰기, 그리고 메모리 사용량 사이에 어떤 균형을 찾고, 데이터의 일관성과 가용성 사이에서 타협적 결정을 내린 설계를 만들었다면 쓸만한 답안일 것이다.
다음의 특성을 갖는 키-값 저장소를 설계 해보자.
- 키-값 쌍의 크기는 10KB 이하이다.
- 큰 데이터를 저장할 수 있어야 한다.
- 높은 가용성을 제공해야 한다. 따라서 시스템은 설사 장애가 있더라도 빨리 응답해야 한다.
- 높은 규모 확장성을 제공해야 한다. 따라서 트래픽 양에 따라 자동적으로 서버 증설/삭제가 이루어져야 한다.
- 데이터 일관성 수준은 조정이 가능해야 한다.
- 응답 지연시간(latency)이 짧아야 한다.
단일 서버 키-값 저장소
키-값 쌍 전부를 메모리에 해시 테이블로 저장하는 방법으로 설계할 수 있다.
이 접근법은 빠른 속도를 보장하나 모든 데이터를 메모리 안에 두는 것이 불가능할 수도 있다는 약점이 있다.
개선책으로는 다음과 같은 것이 있다.
- 데이터 압축(compression)
- 자주 쓰이는 데이터만 메모리에 두고 나머지는 디스크에 저장
이렇게 개선해도, 한 대 서버로는 부족하기에 많은 데이터 저장에는 분산 키-값 저장소(distributed key-value store)가 필요하다.
분산 키-값 저장소
분산 키-값 저장소는 분산 해시 테이블이라고도 불린다.
키-값 쌍을 여러 서버에 분산시키기 때문이다.
CAP 정리(Consistency, Availability, Partition Tolerance theorem)을 이해하고 있어야 한다.
CAP 정리
C - 데이터 일관성(consistency) / A - 가용성(availability) /P - 파티션 감내(partition tolerance)
라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다는 정리이다.
각 요구사항의 명확한 의미는 다음과 같다.
- 데이터 일관성: 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
- 가용성 : 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야 한다.
- 파티션 감내 : 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의마한다. 파티션 감내는 네트워크에 파티션이 생기더라도 시스템은 계속 동작하여야 한다는 것을 뜻한다.

3가지를 모두 만족하지 못하니 어느 두 가지를 만족하느냐에 따라 다음과 같이 분류한다.
- CP 시스템 : 일관성과 파티션 감내를 지원하는 키-값 저장소. 가용성을 희생한다.
- AP 시스템 : 가용성과 파티션 감내를 지원하는 키-값 저장소. 데이터 일관성을 희생한다.
- CA 시스템 : 일관성과 가용성을 지원하는 키-값 저장소. 파티션 감내는 지원하지 않는다. 그러나 통상 네트워크 장애는 피할 수 없는 일로 여겨지므로, 분산 시스템은 반드시 파티션 문제를 감내할 수 있도록 설계되어야 한다. 고로 실세계에 CA 시스템은 존재하지 않는다.
분산 시스템에서 데이터는 보통 여러 노드에 복제되어 보관된다.
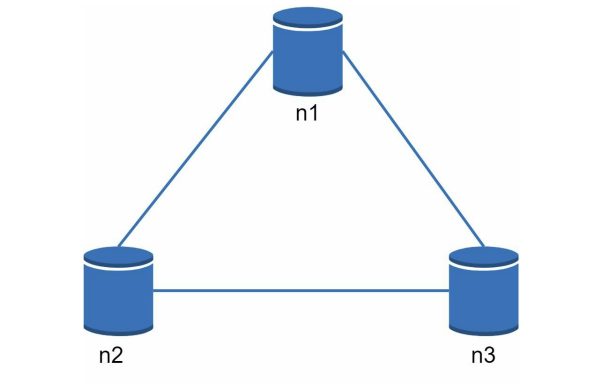
세 대의 복제(replica) 노드 n1, n2, n3에 데이터를 복제하여 보관하는 상황을 가정해보자.
이상적 상태
이상적 환경에라면 네트워크가 파티션되는 상황은 절대로 일어나지 않을 것이다.
n1에 기록된 데이터는 자동적으로 n2와 n3에 복제된다. 데이터 일관성과 가용성도 만족된다.
실세계의 분산 시스템
분산 시스템은 파티션 문제를 피할 수 없다. 그리고 파티션 문제가 발생하면 일관성과 가용성 사이에서 하나를 선택해야 한다.

은행권 시스템이 보통 데이터 일관성을 양보하지 않는다. (오류가 해결될 때까지 가용성을 포기)
일관성 대신 가용성을 선택한 시스템(AP 시스템)은 설사 낡은 데이터를 반환할 위험이 있더라도 계속 읽기 연산을 허용해야 한다.
시스템 컴포넌트
키-값 저장소 구현에 사용될 핵심 컴포넌트 및 기술들을 살펴보자.
- 데이터 파티션
- 데이터 다중화(replication)
- 일관성(consistency)
- 일관성 불일치 해소(inconsistency resolution)
- 장애 처리
- 시스템 아키텍처 다이어그램
- 쓰기 경로(write path)
- 읽기 경로(read path)
널리 사용되는 세 가지 키-값 저장소인 다이나모(Dynamo), 카산드라(Cassandra), 빅테이블(BigTable)의 사례를 참고
데이터 파티션
대규모 애플리케이션의 경우 전체 데이터를 작은 파티션들로 분할한 다음 여러대 서버에 저장한다.
데이터를 파티션 단위로 나눌 때는 다음 두 가지 문제를 중요하게 따져야 한다.
- 데이터를 여러 서버에 고르게 분산할 수 있는가
- 노드가 추가되거나 삭제될 때 데이터의 이동을 최소화할 수 있는가
이 문제를 해결하기에 이전 장에서 다룬 안정 해시(consistent hash)가 적합하다.
안정 해시의 동작 원리를 간략하게 살펴보자.
- 서버를 해시 링(hash ring)에 배치
- 어떤 키-값 쌍을 어떤 서버에 저장할 지 결정하려면 우선 해당 키를 같은 링위에 배치한다. 그 지점으로 부터 링을 시계 방향으로 순회하다 만나는 첫 번째 서버가 바로 해당 키-값 쌍을 저장할 서버다. 따라서 key0은 s1에 저장된다.

안정 해시를 사용해 데이터를 파티션하면 좋은 점
- 규모 확장 자동화(automatic scaling)
- 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제되도록 만들 수 있다.
- 다양성(heterogeneity)
- 각 서버의 용량에 맞게 가상 노드(virtual node)의 수를 조정할 수 있다.
- 고성능 서버는 더 많은 가상 노드를 갖도록 설정할 수 있다.
데이터 다중화 (Data replication)
높은 가용성과 안정성을 확보하기 위해서는 데이터를 N개 서버에 비동기적으로 다중화(replication)할 필요가 있다.
여기서 N은 튜닝 가능한 값이다. N개 서버를 선정하는 방법은 이러하다.
어떤 키를 해시 링 위에 배치한 후, 그 지점으로 부터 시계 방향으로 링을 순회하면서 만나는 첫 N개 서버에 데이터 사본을 보관하는 것이다.
따라서 N = 3으로 설정한 그림 6-5의 예제에서 key0은 s1, s2, s3에 저장된다.

단, 가상 노드를 사용한다면 위와 같이 선택한 N개의 노드가 대응될 실제 물리 서버의개수가 N보다 작아질 수 있다.
이 문제를 피하려면 노드를 선택할 때 같은 물리 서버를 중복 선택하지 않도록 해야 한다.
같은 데이터 센터에 속한 노드는 정전, 네트워크 이슈, 자연재해 등의 문제를 동시에 겪을 가능성이 있다.
따라서 안정성을 담보하기 위해 데이터의 사본은 다른 센터의 서버에 보관하고, 센터들은 고속 네트워크로 연결한다.
데이터 일관성
여러 노드에 다중화된 데이터는 적절히 동기화가 되어야 한다.
정족수 합의(Quorum Consensus) 프로토콜을 사용하면 읽기/쓰기 연산 모두에 일관성을 보장할 수 있다.
정족수는 여러 사람의 합의로 운영되는 의사기관에서 의결을 하는데 필요한 최소한의 참석자 수
정족수 합의 프로토콜은 암호학에서 사용되는 개인들 간에 합의를 도달하는 프로토콜.
이 프로토콜은 분산 환경에서 여러 참여자들이 서로 신뢰할 수 없는 환경에서도 합의를 도출하기 위해 사용됩니다.
관계된 정의 몇 가지
- N = 사본 개수
- W = 쓰기 연산에 대한 정족수
- 쓰기 연산이 성공한 것으로 간주되려면 적어도 W개의 서버로부터 쓰기 연산이 성공했다는 응답을 받아야한다.
- R = 읽기 연산에 대한 정족수
- 읽기 연산이 성공한 것으로 간주되려면 적어도 R개의 서버로 부터 응답을 받아야 한다.

W = 1은 데이터가 한 대 서버에만 기록된다는 뜻이 아니다.
데이터가 s0, s1, s2에 다중화 되는 상황에서 쓰기 연산이 성공했다고 판단하기 위해
중재자(coordinator)는 최소 한 대 서버로부터 쓰기 성공 응답을 받아야 한다는 뜻이다.
따라서 s1으로부터 성공 응답을 받았다면 s0, s2로부터의 응답은 기다릴 필요가 없다.
중재자는 클리이언트와 노드 사이에서 프락시(proxy) 역할을 한다.
W, R, N의 값을 정하는 것은 응답 지연과 데이터 일관성 사이의 타협점을 찾는 전형적인 과정이다.
W = 1 또는 R = 1인 구성의 경우 중재자는 한 대 서버로부터 응답만 받으면 되니 응답속도가 빠르다.
W나 R의 값이 1보다 큰 경우에는 데이터 일관성의 수준은 향상되나 응답속도는 저하된다.
W + R > N인 경우에는 강한 일관성(strong consistency)가 보장된다.
일관성을 보장할 최신 데이터를 가진 노드가 최소 하나는 겹칠 것이기 때문이다.
N, W, R을 정하는 방법
- R = 1, W = N : 빠른 읽기 연산에 최적화된 시스템
- W = 1, R = N : 빠른 쓰기 연산에 최적화된 시스템
- W + R > N: 강한 일관성이 보장됨 ( 보통 N = 3, W = R = 2 )
- W + R <= N : 강한 일관성이 보장되지 않음
일관성 모델
일관성 모델은 키-값 저장소를 설계할 때 고려하는 중요한 요소다.
일관성 수준을 결정하며 다음과 같은 종류가 있다.
이번에는 최종 일관성 모델에 대해 다룹니다.
- 강한 일관성(Strong Consistency)
- 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다.
- 즉 클라이언트는 절대로 낡은(out-of-date) 데이터를 보지 못한다.
- 모든 사본에 현재 쓰기 연산의 결과가 반영될 때까지 해당 데이터에 대한 읽기/쓰기를 금지한다.
- 고가용성 시스템에 적합하지 않음
- 약한 일관성(Weak Consistency)
- 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있다.
- 최종 일관성(Eventual Consistency)
- 약한 일관성의 한 형태
- 갱신 결과가 결국에는 모든 사본에 반영(즉, 동기화)되는 모델
- 다이나모 또는 카산드라 등의 저장소가 채택
- 쓰기 연산이 병렬적으로 발생하면 시스템에 저장된 값의 일관성이 깨질 가능성이 있음
- 이를 클라이언트가 해결해야 함
비 일관성 해소 기법: 데이터 버저닝
데이터 다중화시 가용성이 높아지나 사본 간 일관성이 깨질 가능성이 높이진다.
이를 해결하기 위해 버저닝(Versioning)과 벡터 시계(Vector Clock)을 사용한다.
데이터 일관성이 깨지는 예제 그림
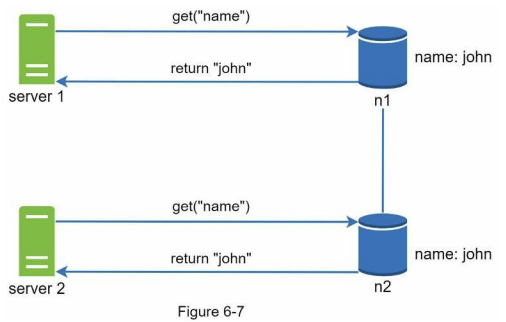
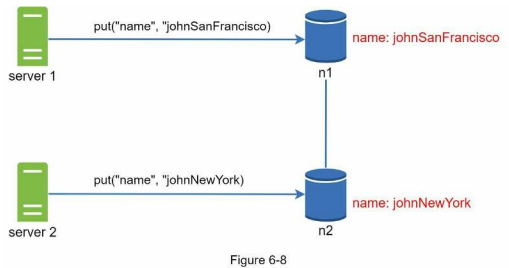
Server1이 "johnSanFrancisco" Server2가 "johnNewYork"으로 이름을 바꿔 충돌하게 되었다.
이를 해결하기 위해 버저닝 시스템을 이용하는데 벡터 시계라는 기술을 이용한다.
벡터 시계란?
[서버, 버전]의 순서쌍을 데이터에 매단 것
어떤 버전이 선행, 후행버전인지 아니면 다른 버전과 충돌이 있는지 판별하기 위해 쓰인다.
D([S1, v1], [S2, v2], ... [Sn, vn])와 같이 표현한다고 가정
D는 데이터, vi는 버전 카운터, Si는 서버 번호
[Si, vi]가 이미 있다면 vi를 증가시킨다.
그렇지 않다면 새 항목 [Si, 1]를 만든다.
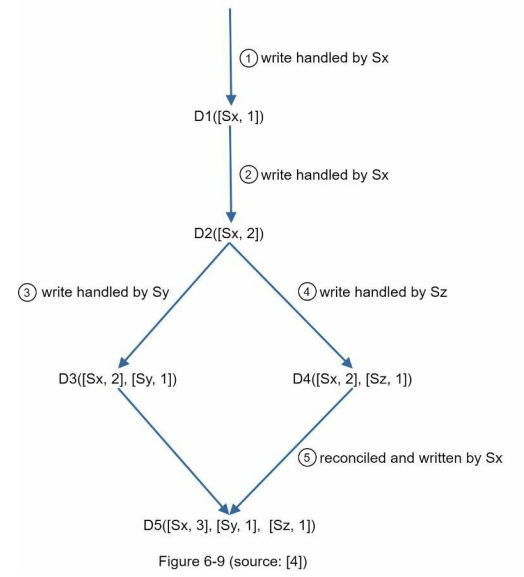
- 1) 클라이언트가 데이터 D1을 시스템에 기록한다. 이 쓰기 연산을 처리한 서버는 Sx이다.
- 따라서 벡터 시계는 D1[(Sx, 1)]으로 변함
- 2) 다른 클라이언트가 데이터 D1을 읽고 D2로 업데이트한 다음 기록한다.
- D2는 D1에 대한 변경이므로 D1을 덮어쓴다. 이때 쓰기 연산은 같은 서버 Sx가 처리한다고 가정하자.
- 벡터 시계는 D2([Sx, 2)]로 바뀐다.
- 3) 다른 클라이언트가 D2를 읽어 D3로 갱신한 다음 기록한다. 이 쓰기연산은 Sy가 처리했다고 가정하자.
- 벡터 시계 상태는 D3([Sx, 2], [Sy, 1])로 바뀐다.
- 4) 또 다른 클라이언트가 D2를 읽고 D4로 갱신한 다음 기록한다.
- 이때 쓰기 연산은 서버 Sz가 처리한다고 가정하자.
- 벡터 시계는 D4([Sx, 2], [Sz, 1])일 것이다.
- 어떤 클라이언트가 D3과 D4를 읽으면 데이터 간 충돌이 있다는 것을 알게된다.
- D2를 Sy와 Sz가 각기 다른 값으로 바꾸었기 떄문이다.
- 이 충돌은 클라이언트가 해소한 후에 서버에 기록한다.
- 이 쓰기 연산을 처리한 서버는 Sx라고 가정
- 벡터 시계는 D5([Sx, 3], [Sy, 1], [Sz, 1])로 바뀐다.
- 충돌이 일어났다는 것을 감지하는 방법을 알아보자.
어떤 버전 X, Y 사이 충돌을 확인하려면
(두 버전이 같은 이전 버전에서 파생된 다른 버전들인지 A -> B / A -> C)
Y의 벡터 시계 구성요소 가운데 X의 벡터 시계 동일 서버 구성요소보다 작은 값을 갖는 것이 있는지 보면 된다.
모든 구성요소가 작은값을 갖는 경우 Y는 X의 이전 버전이다.
벡터 시계를 사용해 충돌을 감지하고 해소하는 방법의 두 가지 단점
- 충돌 감지 및 해소 로직이 클라이언트에 들어가야 하므로, 클라이언트 구현이 복잡해진다.
- [서버: 버전]의 순서쌍 개수가 굉장히 빨리 늘어난다.
- 해결 방안으로는 그 길이에 어떤 임계치(threshold)를 설정하고
- 임계치 이상으로 길이가 길어지면 오래된 순서쌍을 벡터 시계에서 제거하도록 한다.
- 버전 간 선후관계가 정확하게 결정될 수 없어 충돌 해소 과정 효율성이 낮아짐
- 그러나 다이나모 데이터베이스에 관계된 문헌에 따르면 아마존은 그런 문제가 벌어지는 것을 발견하지 못함
장애 처리
대규모 시스템에서 장애는 아주 흔하게 벌어지는 사건이다.
따라서 장애를 어떻게 처리할 것이냐는 굉장히 중요한 문제다.
장애처리를 위한 장애 감지(failure detection)기법과 장애 해소(failure resolution) 전략을 짚어보자.
장애 감지
두 대 이상의 서버가 장애 보고를 하기 위한 멀티캐스팅 채널 구축 / 서버가 많을 때 비효율적

다수의 서버 환경에서 장애 감지를 위한 가십 프로토콜(gossip protocol)
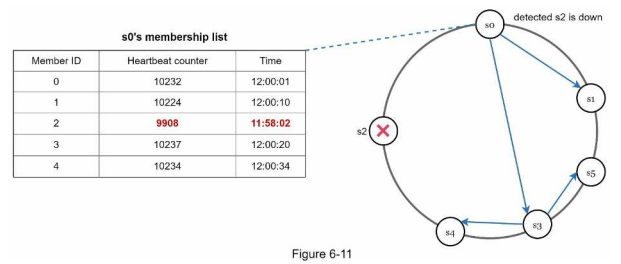
가십 프로토콜의 동작원리
박동 카운터라는 변수를 증가시키며 상호 간 확인하여 갱신 되지 않았다면 장애라고 간주
- 각 노드는 멤버십 목록(membership list)를 유지한다.
- 멤버십 목록은 각 멤버 ID와 그 박동 카운터(heartbeat counter) 쌍의 목록이다.
- 각 노드는 주기적으로 자신의 박동 카운터를 증가시킨다.
- 각 노드는 무작위로 선정된 노드들에게 주기적으로 자기 박동 카운터 목록을 보낸다.
- 박동 카운터 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신한다.
- 어떤 멤버의 박동 카운터 값이 지정된 시간 동안 갱신되지 않으면 해당 멤버는 장애(offline) 상태인 것으로 간주한다.
일시적 장애 처리
가십 프로토콜로 장애를 감지한 시스템은 가용성을 보장하기 위해 필요한 조치를 취해야 한다.
- 엄격한 정족수(stric quorum) 접근법 -> 읽기와 쓰기 연산을 금지
- 느슨한 정족수(sloppy quorum) 접근법
- 임시 위탁 기법(hinted handoff)
- 장애가 해결될 때 까지 장애 해당 서버 이외의 서버에 쓰기 및 읽기 연산을 위탁한다.
- 서버 복구시 일괄 반영하여 데이터 일관성을 보존
- 반영을 원할하기 하기 위해 복구 까지의 쓰기 및 읽기 연산에 hint를 남김

영구 장애 처리
반-엔트로피(anti-entropy) 프로토콜을 구현하여 사본들을 동기화 한다.
반-엔트로피 프로토콜은 사본들을 비교하여 최신버전으로 갱신하는 과정을 포함한다.
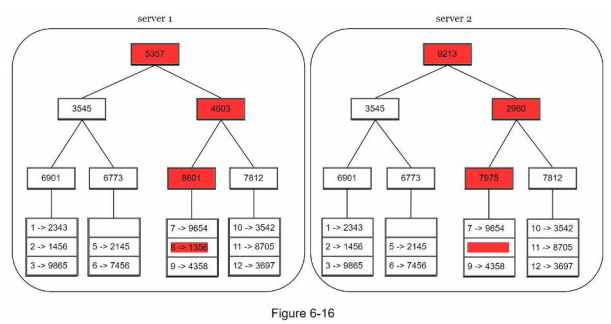
사본 간의 일관성이 망가진 상태를 탐지하고 전송 데이터의 양을 줄이기 위해서 머클(Merkle) 트리를 사용한다.
키 공간(key space)이 1부터 12까지일 때 머클 트리를 만드는 예제
1. 키 공간을 버킷으로 나눈다.
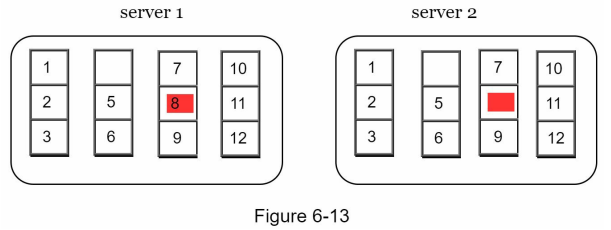
2. 버킷에 포함된 각각의 키에 균등 분포 해시(uniform hash)함수를 적용하여 해시 값을 계산한다.
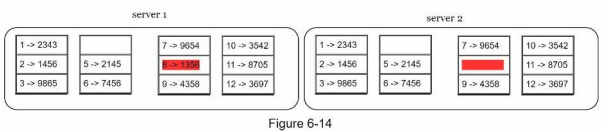
3. 버킷별로 해시값을 계산한 후, 해당 해시 값을 레이블로 갖는 노드를 만든다.
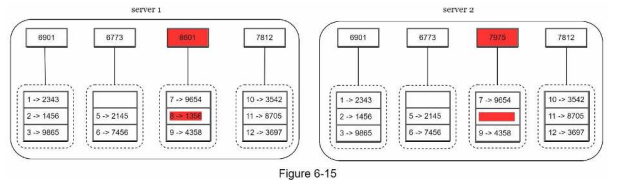
4. 자식 노드의 레이블로부터 새로운 해시 값을 계산하여, 이진 트리를 상향식으로 구성해 나간다.
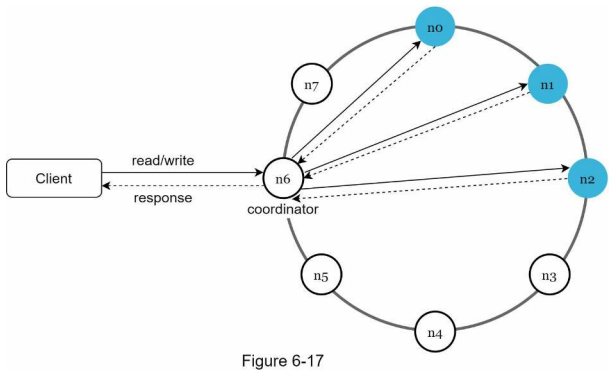
시스템 아키텍쳐 다이어그램
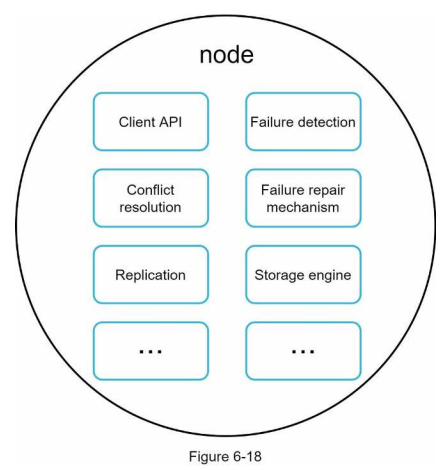
시스템 아키텍쳐 다이어그램의 주된 기능
- 클라이언트는 키-값 저장소가 제공하는 두 가지 단순한 API(GET/PUT)와 통신한다.
- 중재자(coordinator)는 클라이언트에게 키-값 저장소에 대한 프락시(proxy)역할을 하는 노드다.
- 노드는 안정 해시(consistent hash)의 해시 링(hash ring) 위에 분포한다.
- 노드를 자동으로 추가 및 삭제할 수 있도록, 시스템은 완전히 분산된다.(decentralized)
- 데이터는 여러 노드에 다중화된다.
- 모든 노드가 같은 책임을 지므로, SPOF(Single Point of Failure)는 존재하지 않는다.
- 완전 분산 설계를 채택하여 그림 6-18의 기능을 전부를 지원해야 한다.
쓰기 경로
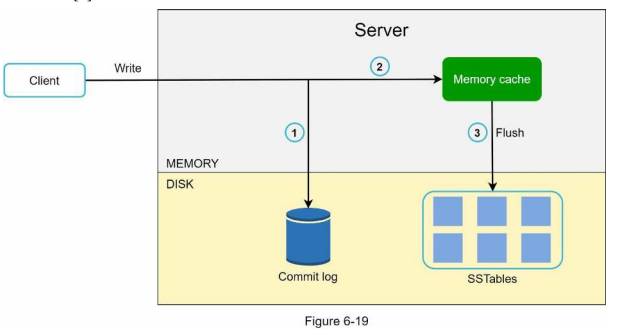
쓰기 연산이 특정 노드에 전달되면 생기는 과정
- 쓰기 요청이 커밋 로그(commit log) 파일에 기록된다.
- 데이터가 메모리 캐시에 기록된다.
- 메모리 캐시가 가득차거나 사전 정의된 임계치에 도달하면 데이터는 디스크에 있는 SSTable에 기록된다.
- SSTable은 Sotred-String Table의 약어, <Key, Value>의 순서쌍을 정렬된 리스트 형태로 관리하는 테이블
읽기 경로
읽기 요청을 받은 노드는 데이터가 메모리 캐시에 있는지 부터 살핀다.
있는 경우 해당 데이터를 아래 그림 6-20과 같이 클라이언트에게 반환한다.

데이터가 메모리에 없는 경우 디스크에서 가져와야 한다.
어느 SSTable에 찾는 키가 있는지 알아내기 위해 블룸 필터(Bloom filter)를 사용한다.
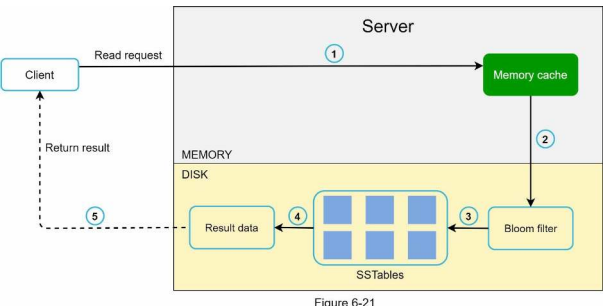
데이터가 메모리에 없을 때 읽기 연산의 처리 경로
- 데이터가 메모리에 있는지 검사한다.
- 데이터가 메모리에 없으므로 블룸 필터를 검사한다.
- 블룸 필터를 통해 어떤 SSTable에 키가 보관되어 있는지 알아낸다.
- SSTable에서 데이터를 가져온다.
- 해당 데이터를 클라이언트에게 반환한다.
요약
| 목표/문제 | 기술 |
| 대규모 데이터 저장 | 안정 해시를 사용해 서버들에 부하 분산 |
| 읽기 연산에 대한 높은 가용성 보장 | 데이터를 여러 데이터센터에 다중화 |
| 쓰기 연산에 대한 높은 가용성 보장 | 버저닝 및 벡터 시계를 사용한 충돌 해소 |
| 데이터 파티션 | 안정 해시 |
| 점진적 규모 확장성 | 안정 해시 |
| 다양성(heterogeneity) | 안정 해시 |
| 조절 가능한 데이터 일관성 | 정족수 합의(quorum consensus) |
| 일시적 장애 처리 | 느슨한 정족수 프로토콜(sloppy quorum)과 단서 후 임시 위탁(hinted handoff) |
| 영구적 장애 처리 | 머클 트리(Merkle tree) |
| 데이터 센터 장애 대응 | 여러 데이터 센터에 걸친 데이터 다중화 |
참고 문헌
- Amazon DynamoDB
- memcached
- Redis
- Dynamo: Amazon's Highly Available Key-value Store
- Cassandra
- Bigtable: A Distributed Storage System for Structured Data
- Merkle tree
- Cassandra architecture
- SSTable
- Bloom filter
'기술 서적 정리 요약 > 가상면접 사례로 배우는 대규모 시스템 설계 기초]' 카테고리의 다른 글
| 5장 안정 해시 설계 (0) | 2023.05.01 |
|---|---|
| 4장 처리율 제한 장치의 설계 (0) | 2023.04.27 |
| 3장 시스템 설계 면접 공략법 (0) | 2023.04.26 |
| 2장 개략적인 규모 측정 (0) | 2023.04.17 |
| 1장. 사용자 수에 따른 규모 확장성 (0) | 2023.04.11 |