한 명의 사용자를 지원하는 시스템에서,
몇백만 사용자를 지원하는 시스템을 설계해보는 과정을 다룹니다.
단일서버 (웹 계층)
웹, 앱, 데이터베이스, 캐시 등이 전부 서버 한 대에서 실행되는 환경
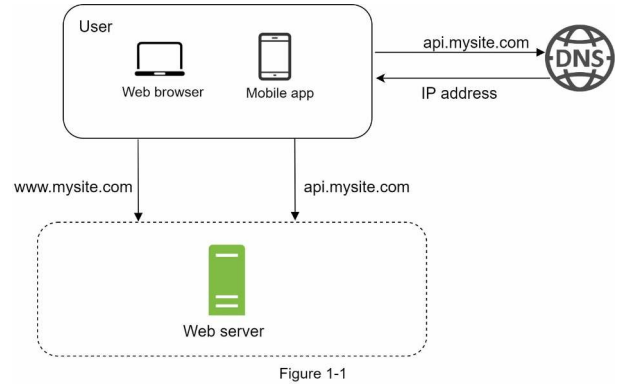

사용자 요청 처리 흐름
- 도메인 이름을 이용해 웹사이트에 접속
- DNS 조회 결과로 IP 주소 반환
- 해당 IP 주소로 HTTP(HyperText Transfer Protocol) 요청이 전달
- 요청을 받은 웹 서버는 HTML 페이지나 JSON 형태의 응답을 반환
데이터베이스 (데이터 계층)
사용자 증가에 대처하기 위해 서버를 증설하는 두 가지 경우
1. 웹/모바일 트래픽 처리
2. 데이터베이스 용
계층을 분리하면 독립적으로 확장할 수 있다.
데이터 베이스 선택
- 관계형 데이터베이스(RDBMS)
- Mysql, Oracle, PostgreSQL 등
- row, column, schema, 데이터 무결성 보장, 유연한 질의 언어
- 비 관계형 데이터베이스(NoSQL)
- CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB 등
- key-value store, graph store, column store, document store로 나뉨
- 비 관계형 데이터베이스를 고려할 상황
- 아주 낮은 응답 지연시간(latency)이 요구됨
- 다루는 데이터가 비정형(unstructured)이라 관계형 데이터가 아님
- 데이터(JSON, YAML, XML 등)를 직렬화 하거나 역직렬화 할 수 있기만 하면 됨
- 아주 많은 양의 데이터를 저장할 필요가 있음
Scale Up vs Scale Out
- Scale Up
- 서버의 성능을 올리는 것 (수직 확장)
- 단순함
- 규모 확장의 한계
- Scale Out
- 서버 증설 (수평 확장) (pay-as-you-grow)
- 아키텍쳐에 대한 높은 이해도 요구
- 여러 노드에 부하를 균등하게 분산시키기 위해 로드 밸런싱(load balancing)이 필
로드밸런서 (load balancer)
- 공개 IP로 접속
- 보안을 위해, 서버 간 통신에는 private IP address가 이용된다.
- Server1이 다운되면 모든 트래픽은 Server2로 전송 -> 전체 웹 사이트 다운 방지
- 두 대의 서버로 감당할 수 없는 트래픽 증가 -> 로드밸런서에 서버 추가 -> 트래픽 분산

데이터베이스 다중화
- 주(master)-부(slave) 관계 설정
- 데이터 원본은 주 서버에, 사본은 부 서버에 저장하는 방식
- 쓰기연산은 마스터에서만 지원 / 부 데이터베이스는 읽기 연산만을 지원
- 더 나은 성능 : master-slave 다중화 모델에서 쓰기 연산과 읽기 연산이 분산 -> 병렬 질의 수 증가 -> 성능 개선
- 안정성(reliability) : 자연 재해 등의 이유로 데이터베이스 서버 가운데 일부가 파괴되어도 데이터 보존
- 가용성(availability) : 하나의 데이터베이스 서버에 장애가 발생해도 지속적 서비스 가능

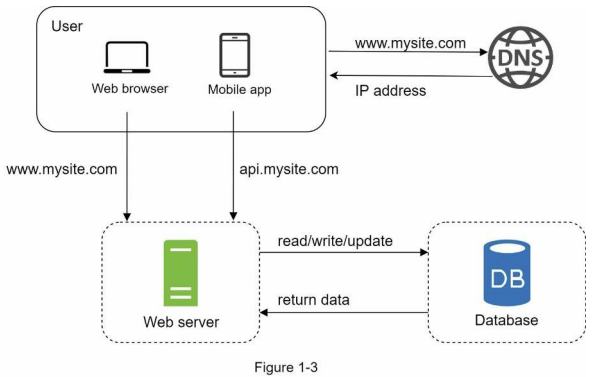
로드밸런서와 데이터베이스 다중화를 고려한 설계안

현재까지의 동작 과정
- 사용자는 DNS로부터 로드밸런서의 공개 IP주소를 받는다.
- 사용자는 해당 IP주소를 사용해 로드밸런서에 접속
- HTTP 요청은 서버 1이나 서버 2로 전달
- 웹 서버는 사용자의 데이터를 부 데이터베이스에서 읽음
- 웹 서버는 데이터 변경 연산은 주 데이터베이스로 전달
캐시 (응답 시간 개선)
값비싼 연산 결과 또는 자주 참조되는 데이터를 메모리 안에 두고,
뒤이은 요청이 보다 빨리 처리될 수 있도록 하는 저장소
캐시를 통해 데이터베이스 호출을 완화하여 애플리케이션의 성능을 향상시킬 수 있다.
캐시 계층
데이터가 잠시 보관되는 곳, 데이터베이스보다 훨씬 빠르다.
별도의 캐시 계층을 두어 성능 개선 및, DB 부하 감소, 캐시 계층의 규모를 독립적으로 확장 가능

주도형 캐시전략 (read-through caching strategy)
캐시에 데이터를 추가하는 시점을 제어함으로써, 캐시 성능을 향상시키는 전략
Prefetching - 캐시에 데이터를 미리 로드 / Promotion - 캐시에 저장된 데이터중 높은 우선순위 데이터 삭제 방지
캐시 사용 시 유의할 점
- 데이터 갱신은 자주 일어나지 않지만, 자주 참조된다면 고려
- 캐시는 휘발성 메모리에 저장하므로, 영속적으로 보관할 데이터 보관은 적합하지 않음
- 적절한 만료 정책을 선택하라
- 원본 데이터와 일관성 유지 고려
- 단일 캐시 서버와 SPOF(Single Point of Failure) 문제를 고려, 여러 지역에 캐시 서버 분산
- 캐시 메모리가 너무 작으면 eviction되니 과할당(overprovision) 으로 방지
- 적절한 방출(Eviction) 정책선택 - LFU, FIFO 등등
콘텐츠 전송 네트워크(CDN)
웹사이트와 애플리케이션의 정적 컨텐츠를 빠르게 전송하기 위한 분산 네트워크
이미지, 비디오, CSS, Javascript 파일 등을 캐시
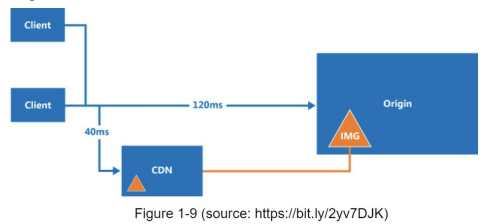

CDN 작동 방식
- 사용자 A가 이미지 등 정적 컨텐츠 요청
- CDN에 이미지가 없다면 원본 서버로 부터 요청
- 원본 서버가 파일을 TTL값과 함께 CDN 서버에 반환
- CDN 서버는 파일을 캐시하고 사용자 A에게 반환
- 사용자 B가 같은 이미지 요청
- 만료되지 않은 이미지에 대한 요청은 캐시를 통해 처리됨
CDN 사용시 고려 사항
- 비용
- 일반적으로 제 3 사업자가 운영하는 CDN은 데이터 전송 양에 따라 요금을 지불한다.
- 자주 사용하지 않는 콘텐츠를 캐싱하면 이득이 크지 않으므로 CDN에서 제외하는 것을 고려
- 적절한 만료 시한 설정
- 시의성이 중요한(time-sensitive) 콘텐츠의 경우 만료 시점을 잘 정해야 한다.
- 장애 대처
- CDN 자체가 죽을 경우를 고려하고 응답하지 않으면 원본 서버로 부터 직접 콘텐츠를 가져오도록 클라이언트를 구성
- 콘텐츠 무효화 방법
- CDN 서비스 사업자가 제공하는 API를 이용해 콘텐츠 무효화
- 콘텐츠의 다른 버전을 서비스 하도록 오브젝트 버저닝 이용
CDN과 Cache가 추가된 설계
- CDN : 정적 콘텐츠를 웹 서버를 통해 서비스 하지 않아 더 나은 성능 보장
- Cache : 데이터베이스 부하 감소

무상태(stateless) 웹 계층
웹 계층의 수평적 확장 방법을 고려하는 단계
수평적 확장을 위해서는 상태 정보(사용자 세션 데이터 등등)을 웹 계층에서 제거해야 한다.
무상태 웹 계층 : 상태 정보를 RDBMS, NoSQL 같은 지속성 저장소에 보관하고, 필요할 때 가져오도록 구성한 웹 계층
상태 정보 의존적인 아키텍쳐
- 상태 정보 보관 서버 : 클라이언트 정보(상태 유지)를 요청들 사이에 공유
- 각 사용자 상태정보는, 각 서버에 저장되어 HTTP 요청을 서버와 일치시켜야 함
- 위 문제 때문에 로드밸런서의 고정 세션(sticky session)기능을 제공하나, 로드밸런서에 부담을 주고 확장성에 불리

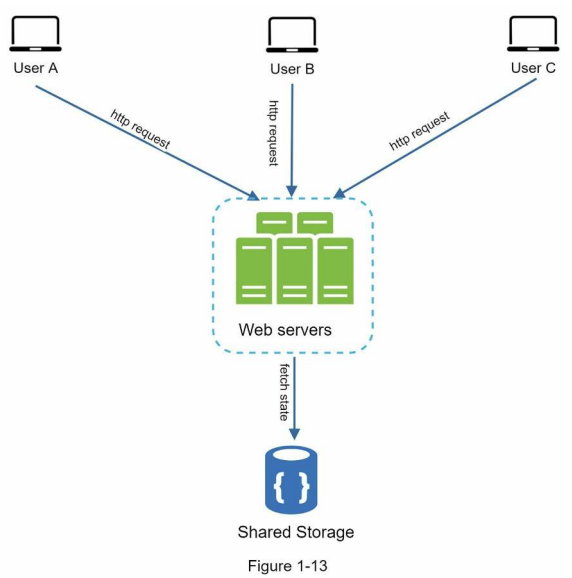
무상태 아키텍쳐
- 사용자의 HTTP 요청은 어떤 웹 서버로도 전달 될 수 있다.
- 상태 정보가 필요한 경우 공유 저장소(shared storage)로 부터 데이터를 가져온다.
- 단순하고, 안정적이며, 규모 확장이 쉽다.

데이터 센터
- 여러 지역에 쾌적한 서비스를 위해 사용
- 지리적 라우팅 - 장애가 없는 상황에서 가장 가까운 데이터 센터로 안내
- geoDNS - 사용자의 위치에 따라 도메인 이름을 어떤 IP 주소로 변환할지 결정할 수 있도록 하는 DNS 서비스
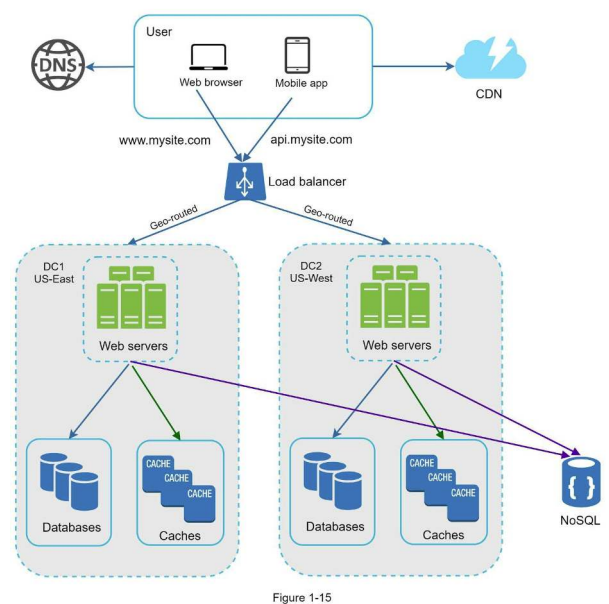
다중 데이터 센터 아키텍쳐 고려사항
- 트래픽 우회 - 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법 고려 (GeoDNS)
- 데이터 동기화(Synchronization)
- 테스트와 배포 - 여러 위치에서 테스트 / 배포 자동화 (동일한 서비스 설치)
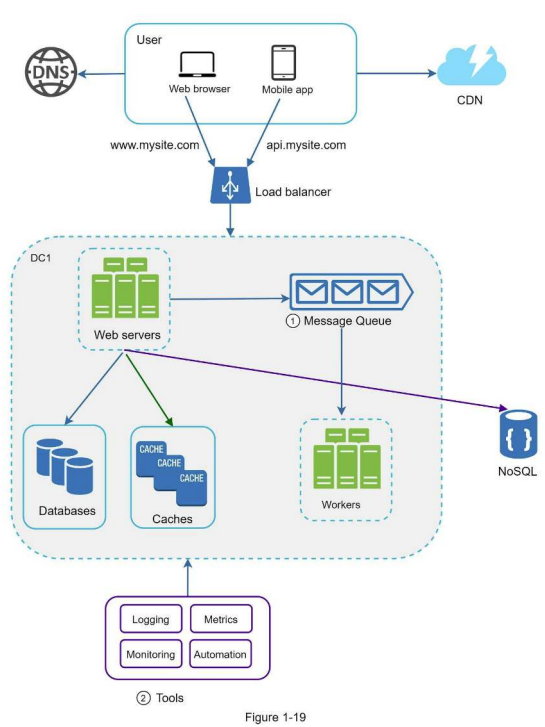
메시지 큐
메시지의 무손실(durability, 메시지 큐에 일단 보관된 메시지는 소비자가 꺼낼 때까지 안전히 보관되는 특성)을 보장하는, 비동기 통신(asynchronous communication)을 지원하는 컴포넌트
메시지의 버퍼 역할을 하며, 비동기적으로 전송한다.
- 생산자/발행자(producer/publisher)가 메시지를 만들어 메시지 큐에 발행(publish)
- 소비자 프로세스가 다운되어도 메시지 발행 가능
- 큐에는 소비자/구독자(consumer/subscriber)가 메시지를 받아 그에 맞는 동작을 수행하는 역할
- 생산자 서비스가 가용한 상태가 아니더라도 메시지 수신 가능

메시지 큐 사용 예시
- 사진 보정 애플리케이션(크로핑/샤프닝/블러링) - 보정 시간이 오래 걸릴 수 있는 프로세스이므로 비동기 처리
- 웹 서버 -> 사진 보정 작업(job)을 메시지 큐에 넣음
- 사진 보정 작업(worker) 프로세스는 메시지 큐에서 꺼내면서 비동기적으로 완료
로그, 메트릭 그리고 자동화
사이트와 함께 사업 규모가 커지면 로그/메트릭/자동화 도구에 필수적으로 투자
- 로그
- 에러 로그 모니터링은 시스템의 오류와 문제들을 쉽게 찾아낼 수 있다.
- 메트릭
- 사업 현황에 관한 유용한 정보/ 시스템의 현재 상태 손쉽게 파악
- 호스트 단위 메트릭 - CPU, 메모리, 디스크 I/O에 관한 메트릭
- 종합(aggregated) 메트릭 - 데이터베이스 계층의 성능, 캐시 계층의 성능 같은 것이 여기 해당
- 핵심 비즈니스 메트릭 - 일별 능동 사용자(daily active user), 수익(revenue), 재방문(retention) 등
- 자동화
- 시스템 비대/복잡해지면 생산성을 높이기 위해 활용
- CI, Build, Test, Deployment 등의 절차 자동화 -> 개발 생산성 향상
메시지 큐 + 로그, 메트릭, 자동화 반영 설계
데이터베이스 규모 확장
저장할 데이터가 많아지는 데이터베이스 부하도 증가
규모 확장은 수직적 규모 확장법과 수평적 규모 확장법이 있다.
- 수직적 확장(Scale up)
- 고성능 자원(CPU, RAM, 디스크 등)을 증설하는 방법 / AWS RDS 옵션 변경 등
- 무한 증설 불가 / SPOF 위험성 / 고 비용
- 수평적 확장(sharding)
- 더 많은 서버를 추가하여 성능 향상
- sharding - 대규모 데이터베이스를 shard라고 부르는 작은 단위로 분할하는 기술
- 모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.

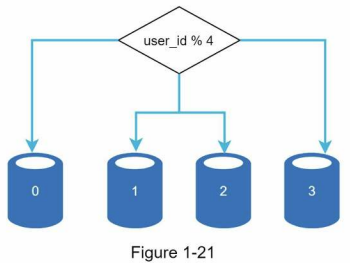

샤딩 전략 고려사항
- 샤딩 키를 어떻게 정할 것인지 (데이터를 고르게 분할)
- 데이터의 재 샤딩(resharding)
- 데이터가 너무 많아 하나의 샤드로 감당하기 어려울 때
- 샤드간 데이터 분포가 비균등 문제
- 샤드 소진(shard exhaustion) -> 샤드 키 계산 함수 변경 / 안정 해시 기법 사용
- 유명 인사 문제(celebrity) - 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제
- 유명인사 각각에 샤드 하나씩을 할당하거나 더 잘개 쪼개기
- 조인과 비정규화(join and de-nomalization)
- 쪼갠 여러 샤드는 조인하기 힘들어 짐
- 데이터베이스 비정규화

백만 사용자, 그리고 그 이상
시스템 규모 확장을 위한 기법 정리
웹 계층은 무상태 계층으로
모든 계층에 다중화 도입
가능한 한 많은 데이터를 캐시할 것
여러 데이터 센터를 지원할 것
정적 콘텐츠는 CDN을 통해 서비스할 것
데이터 계층은 샤딩을 통해 그 규모를 확장할 것
각 계층은 독립적 서비스로 분할할 것
시스템을 지속적으로 모니터링하고, 자동화 도구들을 활용할 것
'기술 서적 정리 요약 > 가상면접 사례로 배우는 대규모 시스템 설계 기초]' 카테고리의 다른 글
| 5장 안정 해시 설계 (0) | 2023.05.01 |
|---|---|
| 4장 처리율 제한 장치의 설계 (0) | 2023.04.27 |
| 3장 시스템 설계 면접 공략법 (0) | 2023.04.26 |
| 2장 개략적인 규모 측정 (0) | 2023.04.17 |
| [가상면접 사례로 배우는 대규모 시스템 설계 기초] 목차 및 후기 (0) | 2023.03.06 |