계기 : 다음은 2020년 2월에, 네이버 실시간 검색어 기능은 2021년 2월 5일부로 사라졌다.
실시간 검색어로 이슈에 대한 정보를 얻었는데 사라져서
여러 포털 사이트에서 정보를 모아서 실시간 검색어 (실검) 기능을 만들어 보려고 한다.
1. 데이터 수집
예전에 노마드 코더에서 파이썬의 Beautiful Soup을 이용해 웹 크롤링을 했었기에
자바 유저이지만 파이썬도 써보고 싶어서 이를 이용해서 정보를 긁어서 데이터베이스에 집어 넣을 것이다.
가져올 페이지로는
- 네이버 뉴스 랭킹 (1시간 간격 업데이트)
- 구글 트렌드 (1시간 마다 업데이트)
- 네이트 (인기검색어 + 실시간 이슈 키워드) (실검 기능 존재)
- 다음 ( 검색어 하단 인기 검색어)
- 줌 (이슈 검색어) (실검 기능 존재)
API를 제공하는 페이지에서는 API를 활용할 예정이며
순위는 1 ~ 10위
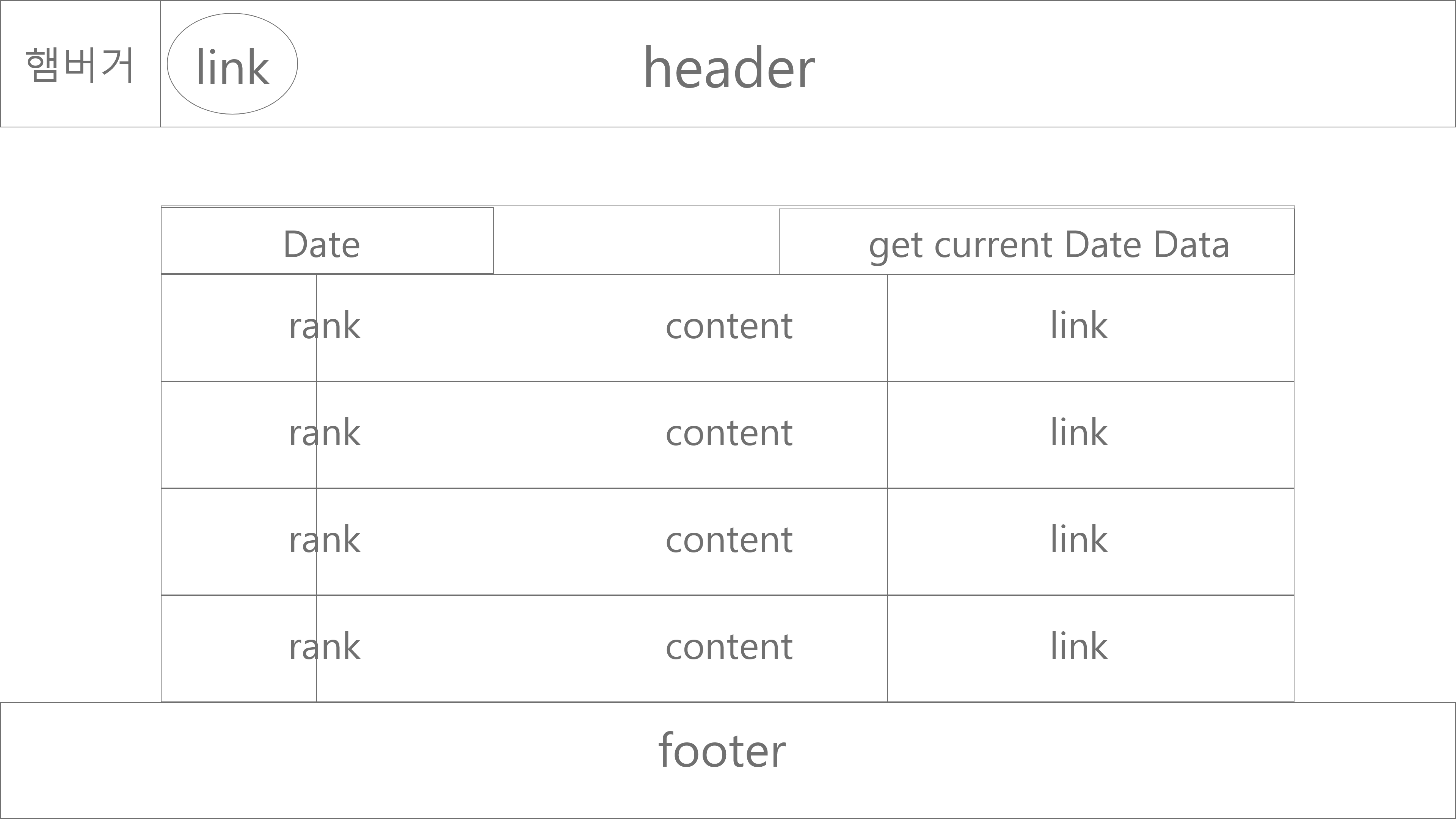
초기에 구성할 시스템으로는 과거의 데이터를 바탕으로 일일 인기검색어 top 10을 제공하고
이후 당일 데이터로 1시간 간격으로 인기 검색어 top 10을 제공하는 것을 목표로 한다.
데이터를 가져오는 시간간격은 30분 정도로 생각하고 있다.
2. 데이터 가공
데이터 가공은 파이썬 혹은 자바에서 할 예정이다.
1차적으로 가공되지 않은 데이터를 각 포털별로 쌓아둔다.
row는 id, potalSite, content, rank ,date로 구성
id unique, autoincrement 옵션을 주고 나머지는 not null 정도로 하려고 한다.
가져온 데이터를 어떻게 가공할지가 고민거리인데
1. 순위별 정렬
2. 각 순위에서 가장 많이 노출된 문자열 솎아내기 (counting)
2-1 -> 각 순위에서 솎아낸 문자열중에 겹치는 부분이 없다면? -> 우선순위 -> 네이버 뉴스 랭킹 or 구글 트렌드 우선하기
3. 솎아낸 문자열 랭킹 기준으로 나만의 랭킹 재정의
정도로 생각하고 있다.
재정의한 데이터를 다른 테이블에 넣어서 데이터 베이스 구축
구축한 데이터 베이스 기반으로 웹에 띄우기 and api제공
3. 검색 기능
검색어를 어떤식으로 제공할지도 생각중이다.
단순히 내가 재정의한 데이터가 존재하면 순위와 일자를 포함하여 return할지
혹은 포털사이트에서 가져온 1차적인 데이터도 포함시켜 해당 순위와 일자 그리고 링크까지 제공할지 -> 가져온 소스 -> too much
4.회원기능
외부 서비스를 기반으로 회원기능 (네이버 카카오 구글) + 이메일 기반 자체 회원기능
5. client side
모바일 & pc 대응
6. 사용할 기술
GIT
크롤링쪽은 python, beautiful soup, mysql or 다른 데이터베이스
데이터 가공은 파이썬이나 자바 뭐 쓸지 생각중 -> 자체 라이브러리를 구축하거나 그럴듯?
웹 -> java15 , springboot ,springboot security, jpa, junit, node, react, javascript, typescript (쓰고싶은거 나열)
일단 이 정도로 생각해두고 내일은 adobe xd로 디자인 대충 생각해보자 (bootstrap으로 구현예정)
크롤링 부터 하즈아아아
'프로젝트 정리 > 실시간 검색어 프로젝트' 카테고리의 다른 글
| #6 Spring Security Guide (공식문서 보고 따라하기) (0) | 2021.09.01 |
|---|---|
| #5 프로젝트 구상 및 기획 ver.2 (0) | 2021.08.26 |
| #4 Crwaling and Robots.txt (0) | 2021.08.26 |
| #3 Practice Jsoup (0) | 2021.08.25 |
| #2 프로젝트 생성 (0) | 2021.08.25 |